Целочисленные двоичные коды
4.6.1. Представление текстовой информации в памяти компьютера
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Вы нажимаете на клавиатуре символьную клавишу, и в компьютер поступает определённая последовательность электрических импульсов разной силы, которую можно представить в виде цепочки из восьми нулей и единиц (двоичного кода).
Мы уже говорили о том, что разрядность двоичного кода i и количество возможных кодовых комбинаций N связаны соотношением: 2 i = N. Восьмиразрядный двоичный позволяет получить 256 различных кодовых комбинаций: 2 8 = 256.
С помощью такого количества кодовых комбинаций можно закодировать все символы, расположенные на клавиатуре компьютера, — строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и т. д., а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, перевод строки, пробел и др.).
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых таблиц.
Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Кодовая таблица содержит коды для 256 различных символов, пронумерованных от 0 до 255. Первые 128 кодов во всех кодовых таблицах соответствуют одним и тем же символам:
- коды с номерами от 0 до 32 соответствуют управляющим символам;
- коды с номерами от 33 до 127 соответствуют изображаемым символам — латинским буквам, знакам препинания, цифрам, знакам арифметических операций и т. д.
Эти коды были разработаны в США и получили название ASCII (American Standart Code for Information Interchange — Американский стандартный для обмена информацией).
В таблице 4.1 представлен фрагмент кодировки ASCII.
В таблице 4.2 представлены десятичные и двоичные коды нескольких букв русского алфавита в двух различных кодировках.
| Кодировка |
||||
11010010 11000101 11001010 11010001 11010010
в кодировке Windows будет соответствовать слово «ТЕКСТ», а в кодировке КОИ-8 — бессмысленный набор символов «рейяр».
Как правило, не должен заботиться о перекодировании текстовых документов, так как это делают специальные про-граммы-конверторы, встроенные в операционную систему и приложения.
Восьмиразрядные кодировки обладают одним серьёзным ограничением: количество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было одновременно пользоваться более чем двумя языками. Для устранения этого ограничения был разработан новый стандарт кодирования символов, получивший название Unicode. В Unicode каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать 65 536 различных символов:
2 16 = 65 536.
Первые 128 символов в Unicode совпадают с таблицей ASCII; далее размещены алфавиты всех современных языков, а также все математические и иные научные символьные обозначения. С каждым годом Unicode получает всё более широкое распространение.
4.6.2. Информационный объём фрагмента текста
Вам известно, что информационный объём сообщения I равен произведению количества символов К в сообщении на информационный вес символа алфавита i: I = K * i.
В зависимости от разрядности используемой кодировки информационный
вес символа текста, создаваемого на компьютере, может быть равен:
- 8 битов (1 ) — восьмиразрядная кодировка;
- 16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и т. д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине - только один.
Решение. В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста - 57 байтов.
Ответ: 57 байтов.
Задана 2. В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём текста из 24 символов в этой кодировке.
Решение. I = 24 * 2 = 48 байтов.
Ответ: 48 байтов.
Задача 3. Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 8-битовом коде, в 16-битовую кодировку Unicode. При этом информационное сообщение увеличилось на 2048 байтов. Каков был информационный объём сообщения до перекодировки?
Решение. Информационный вес каждого символа в 16-битовой кодировке в два раза больше информационного веса символа в 8-битовой кодировке. Поэтому при перекодировании исходного блока информации из 8-битовой кодировки в 16-битовую его информационный объём должен был увеличиться вдвое, другими словами, на величину, равную исходному информационному объёму. Следовательно, информационный объём сообщения до перекодировки составлял 2048 байтов = 2 Кб.
Ответ: 2 Кб.
Задана 4. Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение. Информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов во всём словаре равно 740 * 80 * 60 = 3 552 000. Следовательно, объём этого текста в байтах равен 3 552 000 байтов = 3 468,75 Кбайт = 3,39 Мбайт.
Ответ: 3,39 Мбайт.
Ответы на "Вопросы и Задания" после параграфа
О двоичной системе и кодах
В цифровой технике передаваемую, принятую или преобразованную информацию выражают набором символов двоичной системы счисления- двоичным кодом.
Любое привычное нам десятичное число может быть представлено как совокупность единиц и нулей этой системы. Десятичное число 7, например, в двоичной системе пишут так: 0111. Здесь крайний левый символ- старший разряд, а крайний правый символ-младший разряд четырехразрядного двоичного кодового числа. Перевод этого двоичного числа в число десятичной системы счисления выполняют в таком порядке: 0111=0X2 3 +1X2 2 +1X2 1 +1Х2 0 =0+4+2+1 =7.
В основе преобразования двоичного числа в десятичное лежит число 2. Сам же код в этом случае называют двоичным натуральным или кодом 8-4-2-1.
Переводить десятичные числа в двоичные и обратно в пределах четырехразрядного кода вам поможет таблица 1.
Таблица 1
| Десятичное число | Двоичное число |
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
| 10 | 1010 |
| 11 | 1011 |
| 12 | 1100 |
| 13 | 1101 |
| 14 | 1110 |
| 15 | 1111 |
Чтобы прочнее закрепить в памяти принцип кодирования цифровой информации в двоичной системе, предлагаем опытным путем проанализировать работу четырехразрядного двоичного счетчика, собранного, например, на JK-триггерах по схеме, приведенной на рис. 1.
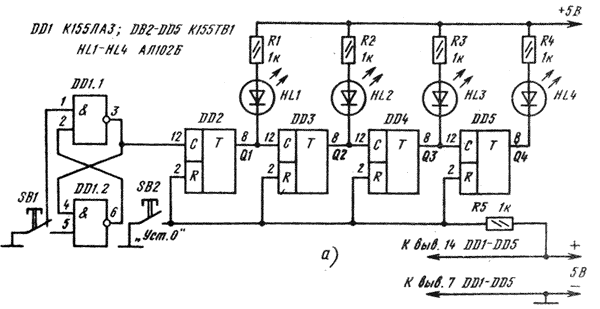
Рис. 1 Четырехразрядный счетчик
Все детали счетчика смонтируйте на макетной панели. К прямым выходам всех триггеров подключите светодиоды или иные индикаторы, по которым можно было бы визуально наблюдать за логическими состояниями триггеров. Функцию источника входных счетных импульсов большой длительности выполняет RS-триггер, собранный на логических элементах 2И-НЕ DD1.1, DD1.2 и управляемый кнопкой SB1.
Заготовьте таблицу (табл. 2), в которую символами двоичной системы счисления будете записывать логические состояния триггеров счетчика импульсов. В крайней левой колонке "Счет"сразу же запишите порядковые номера входных импульсов от 0 до 15. Во второй колонке слева (Q1) записывайте логическое состояние первого триггера при каждом очередном импульсе, в третьей колонке (Q2) - логическое состояние второго триггера и т. д.
Итак, проверьте монтаж, надежность паек и, если ошибок не обнаружите, включите питание. При этом некоторые светодиоды могут загореться, сигнализируя о том, что относящиеся к ним триггеры в момент включения питания оказались в единичном состоянии. Нажмите на кнопку SB2, чтобы. на вход R триггеров подать напряжение низкого уровня и тем самым установить все триггеры счетчика в нулевое состояние. Теперь все индикаторы погасли. Это логическое состояние всех триггеров четырехразрядного счетчика импульсов обозначьте в таблице нулями.
Таблица 2
| Счет | Q1 | Q2 | Q3 | Q4 |
| 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 |
| 3 | 1 | 1 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 |
| 5 | 1 | 0 | 1 | 0 |
| 6 | 0 | 1 | 1 | 0 |
| 7 | 1 | 1 | 1 | 0 |
| 8 | 0 | 0 | 0 | 1 |
| 9 | 1 | 0 | 0 | 1 |
| 10 | 0 | 1 | 0 | 1 |
| 11 | 1 | 1 | 0 | 1 |
| 12 | 0 | 0 | 1 | 1 |
| 13 | 1 | 0 | 1 | 1 |
| 14 | 0 | 1 | 1 | 1 |
| 15 | 1 | 1 | 1 | 1 |
Теперь кратковременно нажмите и отпустите кнопку SB1. При этом RS-триггер переключится из нулевого состояния в единичное сам и напряжением высокого уровня на прямом выходе переключит в такое же состояние первый триггер счетчика. В результате включится светодиод HL1. Остальные триггеры счетчика будут сохранять нулевое состояние, и их светодиоды, естественно, светить не должны.
Запишите это состояние триггеров в таблицу: в колонку Ql-1, в остальные-0. Нажмите второй раз на кнопку SB1, имитируя второй входной импульс. Сразу же погаснет первый светодиод и включится второй - HL2. Теперь в единичном состоянии оказался второй триггер, а остальные в нулевом. Запишите эти логические состояния триггеров в строку, соответствующую второму входному импульсу.
Третий входной импульс снова установит первый триггер счетчика в единичное состояние и не изменит состояние второго триггера, поэтому будут светить индикаторы HL1 и HL2. В таблице такое состояние счетчика запишите в таком виде: 1100. При четвертом входном импульсе будет светить только светодиод HL3, а в таблице должна появиться запись 0010.
Так, не торопясь, нажимая на кнопку SB1 и считывая по свечению индикаторов состояния триггеров, вы постепенно заполните всю таблицу логических состояний четырехразрядного счетчика. После этого отключите RS-триггер от входа счетчика и подайте на него от генератора последовательность импульсов, следующих с частотой 1...2 Гц. Порядок вспахивания индикаторов, который при такой частоте можно проследить, подтвердит ваши записи, характеризующие работы двоичного четырехразрядного счетчика.
Подведем итоги. Первый триггер вашего опытного счетчика представляет собой младший разряд, а четвертый - старший разряд четырехразрядного счетчика. Соответственно расположены в таблице и колонки символов логических состояний триггеров. Но в двоичной системе символы младших разрядов по отношению к старшим располагают с правой стороны. Поэтому, чтобы по составленной вами таблице определить кодовое состояние счетчика при каждом из пятнадцати входных импульсов, записи в ней следует читать справа налево или предварительно таблицу перевернуть зеркально.
В результате получится: при первом входном импульсе-0001, при втором-0010, при третьем-0011 и т. д. до пятнадцатого импульса, когда кодовое состояние счетчика будет 1111, после чего счет импульсов повторяется. Короче говоря, эта таблица кода состояния счетчика, но, конечно, в перевернутом виде..
Подобные опыты с соответствующими выводами можно, разумеется, провести и с четырехразрядным счетчиком на D-триггерах, соединив их инверсные выходы с входами D, чтобы триггеры работали в счетном режиме. Полезно провести такое исследование и с микросхемой К155ИЕ2. Включив ее по схеме, изображенной на рис. 2, можно составить таблицу кодовых состояний такого счетчика импульсов от 0 до 9.
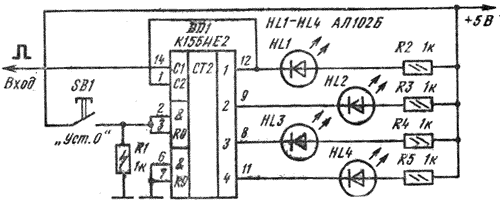
Рис. 2 Опыт с микросхемой К155ИЕ2
Как вы уже знаете, максимальное десятичное число, которое можно выразить двоичным четырехразрядным кодом,-15. А если это число трехзначное, например, 137? В двоичном коде оно будет выглядеть громоздко и не всегда удобно для переработки: 10001001. Поэтому в цифровой технике, кроме двоичного кода, применяют еще код двоично-десятичный, где каждую цифру десятичного числа представляют в двоичном виде. При двоично-десятичном коде то же трехзначное число 137 имеет такой вид:
А каким образом двоичные или двоично-десятичные кодовые состояния счетчиков импульсов переводят в цифры десятичной системы счисления? Это выполняется с помощью дешифраторов и знакосинтезирующих индикаторов.
Читайте и пишите полезныеБеззнаковые двоичные коды
Первый вид двоичных кодов, который мы рассмотрим - это целые беззнаковые коды. Для определённости примем длину слова процессора равной восьми битам. В этих кодах каждый двоичный разряд представляет собой степень цифры 2:
При этом минимально возможное число, которое можно записать таким двоичным кодом, равно 0. Максимально возможное число, которое можно записать таким двоичным кодом, можно определить как:

Этими двумя числами полностью можно определить диапазон, чисел которые можно представить таким двоичным кодом. В случае двоичного восьмиразрядного беззнакового целого числа диапазон будет: диапазон чисел, которые можно записать таким кодом: 0 .. 255. Для шестнадцатиразрядного кода этот 0 .. 65535. В восьмиразрядном процессоре для хранения такого числа используется две ячейки памяти, расположенные в соседних адресах. Для работы с такими числами используются специальные команды.
Прямые знаковые двоичные коды
Второй вид двоичных кодов, который мы рассмотрим - это прямые целые знаковые коды. В этих кодах старший разряд в слове используется для представления знака числа. В прямом знаковом коде нулем обозначается знак "+", а единицей - знак "-". В результате введения знакового разряда диапазон чисел смещается в сторону отрицательных чисел:

В случае двоичного восьмиразрядного знакового целого числа диапазон чисел, которые можно записать таким кодом: -127 .. +127. Для шестнадцатиразрядного кода этот диапазон будет: -32767 .. +32767. В восьмиразрядном процессоре для хранения такого числа тоже используется две ячейки памяти, расположенные в соседних адресах.
Недостатком такого кода является то, что знаковый разряд и цифровые разряды приходится обрабатывать раздельно. Алгоритм программ, работающий с такими кодами получается сложный. Для выделения и изменения знакового разряда приходится применять механизм маскирования разрядов, что резко увеличивает размер программы и уменьшает ее быстродействие. Для того, чтобы алгоритм обработки знакового и цифровых разрядов не различался, были введены обратные двоичные коды.
Знаковые обратные двоичные коды.
Обратные двоичные коды отличаются от прямых только тем, что отрицательные числа в них получаются инвертированием всех разрядов числа. При этом знаковый и цифровые разряды не различаются. Алгоритм работы с такими кодами резко упрощается.

Тем не менее при работе с обратными кодами требуется специальный алгоритм распознавания знака, вычисления абсолютного значения числа, восстановления знака результата числа. Кроме того, в прямом и обратном коде числа для запоминания числа 0 используется два кода, тогда как известно, что число 0 положительное и отрицательным не может быть никогда.
Знаковые дополнительные двоичные коды.
От перечисленных недостатков свободны дополнительные коды. Эти коды позволяют непосредственно суммировать положительные и отрицательные числа не анализируя знаковый разряд и при этом получать правильный результат. Все это становится возможным благодаря тому, что дополнительные числа являются естественным кольцом чисел, а не исскуственным образованием как прямые и обратные коды. Кроме того немаловажным является то, что вычислять дополнение в двоичном коде чрезвычайно легко. Для этого достаточно к обратному коду добавить 1:

Диапазон чисел, которые можно записать таким кодом: -128 .. +127. Для шестнадцатиразрядного кода этот диапазон будет: -32768 .. +32767. В восьмиразрядном процессоре для хранения такого числа используется две ячейки памяти, расположенные в соседних адресах.
В обратных и дополнительных кодах наблюдается интересный эффект, который называется эффект распространения знака. Он заключается в том, что при преобразовании однобайтного числа в двухбайтное достаточно всем битам старшего байта присвоить значение знакового бита младшего байта. То есть для хранения знака числа можно использовать сколько угодно старших бит. При этом значение кода совершенно не изменяется.
Использование для представления знака числа двух бит предоставляет интересную возможность контролировать переполнения при выполнении арифметических операций. Рассмотрим несколько примеров.
1) Просуммируем числа 12 и 5

В этом примере видно, что в результате суммирования получается правильный результат. Это можно проконтролировать по флагу переноса C, который совпадает со знаком результата (действует эффект распространения знака).
2) Просуммируем два отрицательных числа -12 и -5
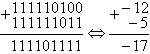
В этом примере флаг переноса C тоже совпадает со знаком результата, то есть переполнения не произошло и в этом случае
3) Просуммируем положительное и отрицательное число -12 и +5
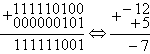
В этом примере при суммировании положительного и отрицательного числа автоматически получается правильный знак результата. В данном случае знак результата отрицательный. Флаг переноса совпадает со знаком результата, поэтому переполнения не было (мы можем убедиться в этом непосредственными вычислениями на бумаге или на калькуляторе).
4) Просуммируем положительное и отрицательное число +12 и -5
![]()
В данном примере знак результата положительный. Флаг переноса совпадает со знаком результата, поэтому переполнения не было и в этом случае.
5)Просуммируем числа 100 и 31
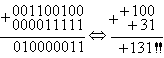
В этом примере видно, что в результате суммирования произошло переполнение восьмибитовой переменной, т.к. в результате операции над положительными числами получился отрицательный результат. Однако если рассмотреть флаг переноса, то он не совпадает со знаком результата. Эта ситуации является признаком переполнения результата и легко обнаруживается при помощи операции "исключающее ИЛИ" над старшим битом результата и флагом переноса C. Большинство процессоров осуществляют эту операцию аппаратно и помещают результат во флаг переполнения OV.
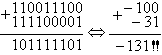
В этом примере результате операции над отрицательными числами в результате суммирования произошло переполнение восьмибитовой переменной, т.к. получился положительный результат. И в этом случае если рассмотреть флаг переноса C, то он не совпадает со знаком результата. Отличие от предыдущего случая только в комбинации этих бит. В примере 5 говорят о переполнении результата (комбинация 01), а в примере 6 об антипереполнении результата (комбинация 10).
Литература:
Другие виды двоичных кодов:
Иногда бывает удобно хранить числа в памяти процессора в десятичном
виде
http://сайт/proc/DecCod.php
Стандартные форматы чисел
с плавающей запятой для компьютеров и микроконтроллеров
http://сайт/proc/float/
Представление текстов в памяти компьютеров и микроконтроллеров
http://сайт/proc/text.php
В настоящее время и в технике и в быту широко используются как
позиционные, так и непозиционные системы счисления.
.php